
How to Transition from DevOps to MLOps in the AI Era

DevOps Skills Are More Relevant Than Ever
The AI era didn't replace infrastructure engineering—it made it harder to skip. Every LLM feature, RAG pipeline, and fine-tuned model still needs containers, CI/CD, secrets management, observability, and cost controls. The teams shipping AI to production aren't just data scientists; they're engineers who know how to run software reliably.
If you're a DevOps or platform engineer watching the MLOps wave, you're already closer than you think. You understand pipelines, environments, monitoring, and incident response. MLOps adds a new layer—data, models, and non-deterministic behavior—but the operational mindset transfers directly.
This guide is for engineers and engineering leaders at mid-market companies (roughly 20–50 employees) who want to move from DevOps into MLOps without starting from zero.
What MLOps Is (and Isn't)
MLOps is the practice of taking machine learning from experiments to production with the same rigor you apply to application deployments. It covers:
- Reproducibility: Can you rebuild this model six months from now?
- Versioning: Code, data, and model artifacts tracked together
- Deployment: Serving models as APIs, batch jobs, or embedded pipelines
- Monitoring: Tracking accuracy, latency, drift, and cost in production
MLOps is not becoming a data scientist. You don't need to derive loss functions or publish papers. You need to make ML systems deployable, observable, and maintainable—the same job you've been doing for web apps and microservices.
What Transfers Directly from DevOps
Most of your existing toolkit applies without modification:
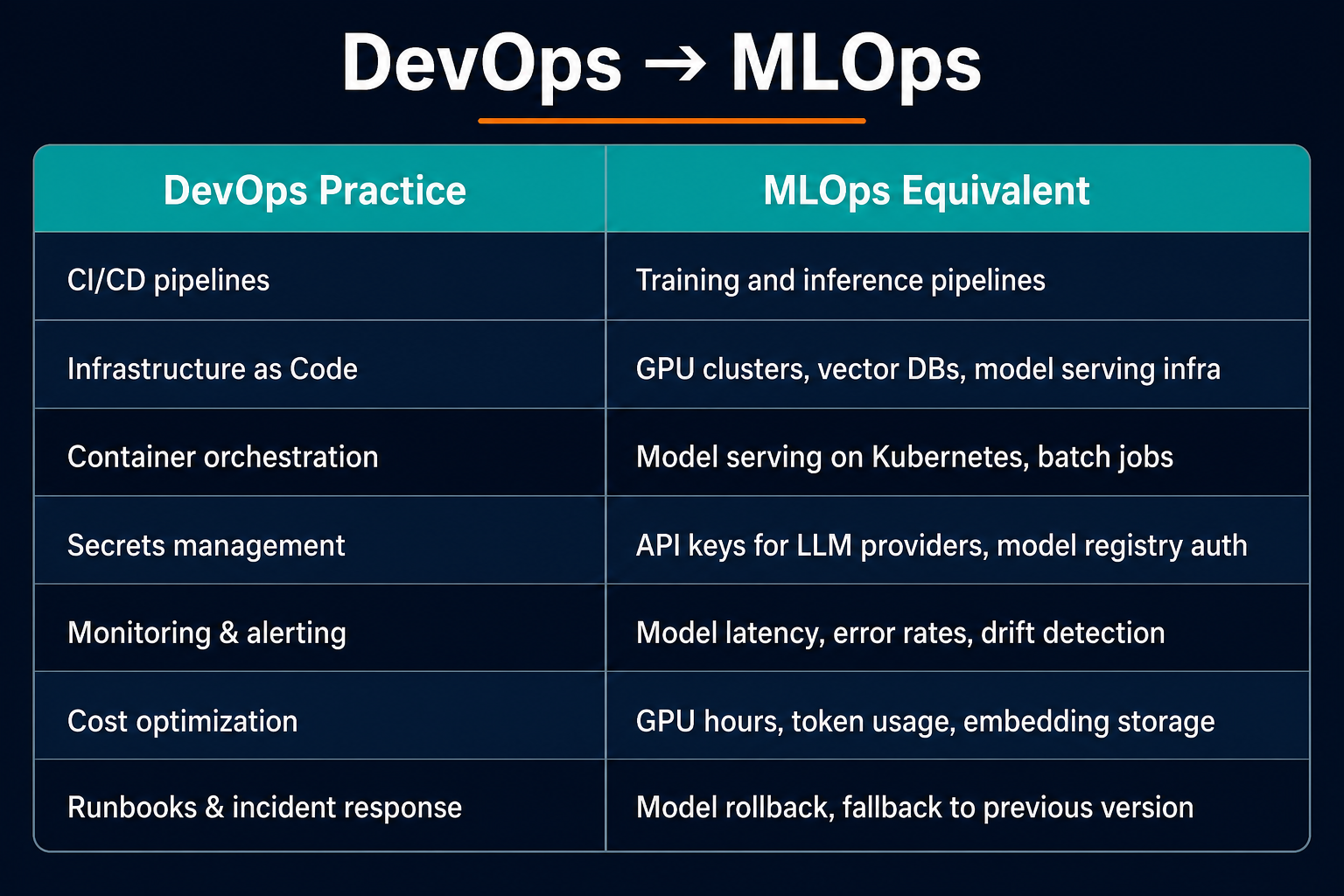
If you've built a GitHub Actions pipeline, deployed to ECS or Kubernetes, and set up Datadog or Grafana dashboards, you've done 60% of what an MLOps platform needs. The remaining 40% is learning how ML artifacts behave differently from traditional software.
What's Genuinely Different
1. Data is a first-class artifact
In traditional DevOps, your inputs are code and config. In MLOps, training data is part of the release. A model trained on January data behaves differently from one trained in June. You need tools like DVC, lakeFS, or cloud-native data versioning—and you need to treat dataset changes with the same review process as code changes.
2. Experiments are messy (and that's OK)
Data scientists run dozens of experiments before picking a model. Your job isn't to stop that—it's to give experiments structure: tracked parameters, logged metrics, reproducible environments, and a clear path from "best experiment" to "production candidate."
Tools like MLflow, Weights & Biases, or Neptune handle experiment tracking. Your DevOps contribution is making sure those tools integrate with your existing CI/CD and access controls.
3. Models degrade silently
A deployed API either works or returns 500. A deployed model can return 200 with wrong answers—and nobody notices until a business metric drops. This is model drift, and it's the biggest operational gap most DevOps teams underestimate.
Monitoring must go beyond uptime and latency. You need:
- Data drift detection: Are input distributions shifting?
- Prediction monitoring: Are output distributions changing?
- Business metric tracking: Is the model still delivering value?
4. Non-deterministic behavior
The same prompt can produce different outputs. Tests that assert exact strings fail. Your testing strategy shifts from deterministic assertions to evaluation frameworks: golden datasets, LLM-as-judge scoring, human review loops, and A/B comparisons between model versions.
The LLM and RAG Era: New MLOps Challenges
Generative AI and RAG (Retrieval-Augmented Generation) added a new category of production systems that look like software but behave like ML:
RAG pipelines combine embedding models, vector databases, retrieval logic, and LLM calls into a single inference path. Each layer can fail independently:
- Embeddings go stale when source documents change
- Vector DB indexes need rebuilding and versioning
- LLM provider APIs change pricing, rate limits, and model behavior without notice
- Prompt templates are code that needs versioning and testing
LLM serving introduces cost dynamics DevOps teams haven't seen before:
- Token-based billing that scales with usage, not infrastructure
- Latency that varies wildly based on output length
- Caching strategies (semantic caching, prompt caching) that directly affect cost and quality
If your company is building internal AI tools, chatbots, or document search, you're already doing MLOps—even if nobody called it that. The RAG stack with Postgres and Lambda is a concrete example of how DevOps patterns apply to AI workloads.
Top 10 MLOps Tools You Need to Know
You don't need to master the entire ecosystem. These are the tools that show up most in mid-market teams—and where your time pays off first:
- MLflow — Experiment tracking, model registry, and deployment. The most common entry point for teams moving beyond notebooks.
- DVC — Version control for datasets and training pipelines. Think Git, but for ML data and artifacts.
- Argo Workflows — ML pipeline orchestration on Kubernetes. Fits naturally if you already operate K8s clusters. On ECS, the equivalent is Step Functions + EventBridge.
- FastAPI — Lightweight HTTP wrapper for serving models. Ideal for a first deploy before scaling to dedicated infra.
- KServe — Model serving on Kubernetes with autoscaling, canary deployments, and multi-framework support. On ECS, use Fargate + ALB with versioned task definitions.
- Prometheus + Grafana — Latency, throughput, and error rate metrics for inference. Same stack you already use for apps.
- Evidently AI — Data drift detection and model quality monitoring in production.
- Great Expectations — Data quality validation in pipelines. Catches "garbage in, garbage out" before training runs.
- pgvector / Milvus — Embedding storage and retrieval for RAG pipelines. pgvector if you already run Postgres; Milvus when you need scale.
- Terraform — Reproducible infrastructure for training environments, serving, and artifact storage.
Start with MLflow + FastAPI + your existing CI/CD. On ECS, Fargate + ECR + ALB cover serving; add the rest when production pain demands it—not before.
Conclusion
Moving from DevOps to MLOps isn't a career pivot—it's the same job with different artifacts. Pipelines, containers, monitoring, and reliable deployments remain the core; what's new is treating data, models, and LLMs as living systems that degrade, shift in cost, and need versioning.
You don't need to master all ten tools at once. Deploy one model, track it with MLflow, and monitor something beyond uptime. That's MLOps in practice—the rest you build when a real use case demands it.
Build what's next.
Ready to improve your cloud infrastructure and operations? Book an assessment with no commitment.
Book assessment