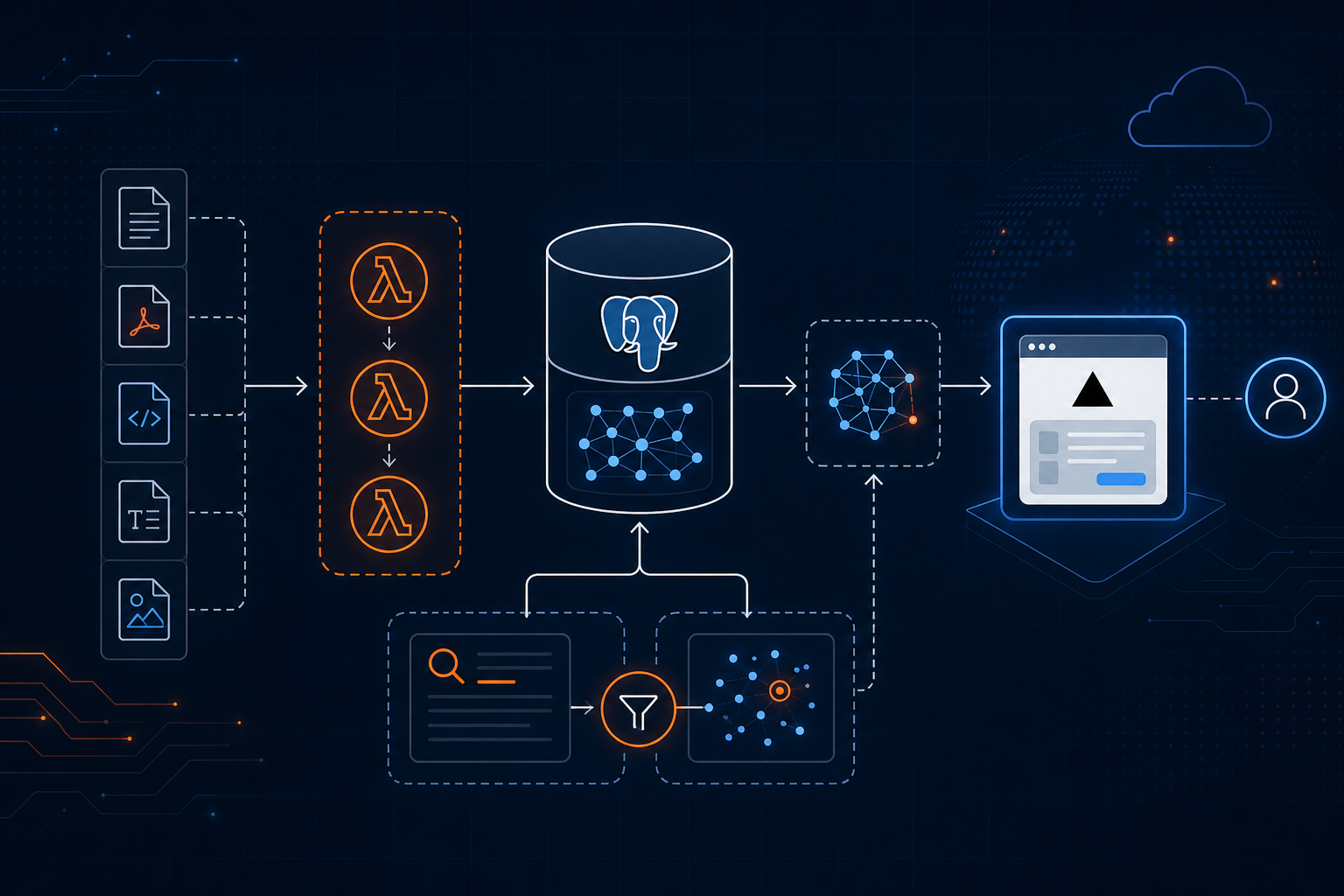
How to Build a Cost-Efficient RAG System with Postgres, Lambda and Vercel

Most RAG tutorials assume you will spin up a vector database, a GPU instance, and a managed embedding API—and then wonder why the bill hits hundreds of dollars before you reach production. You do not need that stack to ship something that works at scale.
We recently built a retrieval-augmented generation system for a client with more than 500,000 articles. The entire platform—embeddings, hosting, and Lambda executions—costs $3.75 per month. This article explains the architecture and the decisions that made that number possible.
Your Answers Are Only as Good as Your Retrieval
Teams often obsess over which LLM to use—GPT-4, Claude, Llama—and treat retrieval as an afterthought. That is backwards. The quality of a RAG response is bounded by the quality of the chunks you feed the model. If retrieval returns irrelevant, outdated, or incomplete context, even the best LLM will hallucinate, hedge, or give a vague answer. Garbage in, garbage out—but the "garbage" is usually a retrieval problem, not a generation problem.
In practice, most disappointing RAG demos trace back to one of these:
- Wrong chunks retrieved — semantically similar but factually wrong for the question
- Missing chunks — the answer exists in the corpus but never surfaces in top-k results
- Dirty data — duplicates, stale versions, broken formatting, or content without enough context to stand alone
- No metadata filtering — searching the entire corpus when the answer lives in one category or time range
Retrieval is the product. The LLM is the presentation layer. Invest your engineering time accordingly: clean the corpus, chunk it well, and measure whether the right chunks appear in your top results before you upgrade models.
The Stack at a Glance
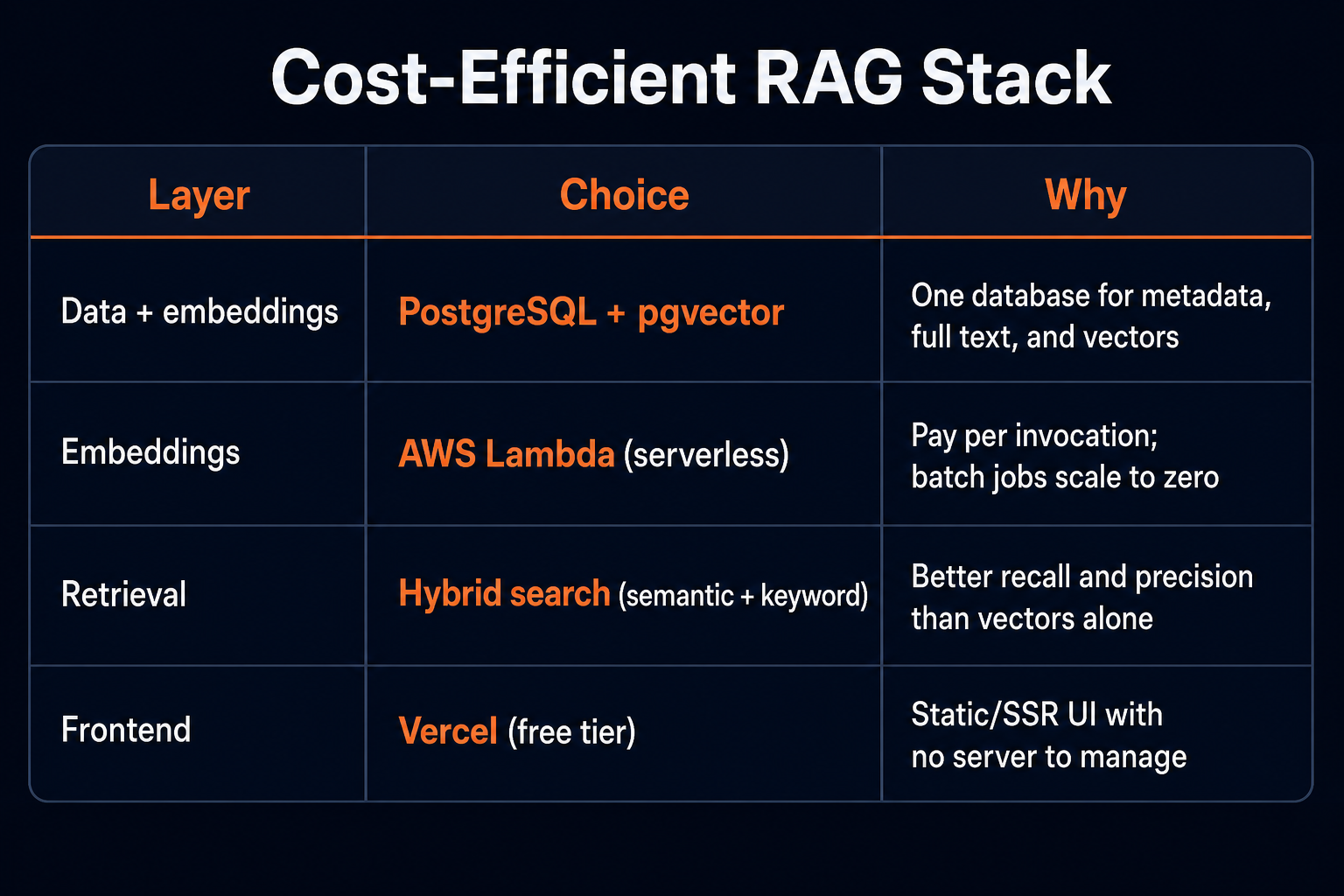
The goal is not to minimize cost at the expense of quality. It is to avoid paying for infrastructure you do not need until you actually need it.
Why Postgres Instead of a Dedicated Vector Database
Dedicated vector databases (Pinecone, Weaviate, Qdrant Cloud, etc.) are excellent when you need sub-10ms latency at billions of vectors with heavy concurrent query load. For many RAG workloads—especially internal tools, content search, and knowledge bases with hundreds of thousands to low millions of documents—PostgreSQL with pgvector is enough and dramatically cheaper.
What you store in one place:
- Article metadata (title, slug, category, timestamps)
- Full article text (for display and keyword search)
- Embedding vectors (typically 384–1536 dimensions depending on model)
- Optional: chunk boundaries, source URLs, access control flags
Why this matters for cost:
- You already know how to operate Postgres (backups, replication, monitoring)
- No second system to sync, secure, and pay for
- Managed Postgres on RDS, Neon, or Supabase starts small and scales predictably
- Hybrid retrieval (below) is natural:
tsvectorfor keyword search lives besidevectorcolumns
For our client, a single Postgres instance holds all 500k+ article records, their chunks, and embeddings. No data duplication across a vector DB and an OLTP database.
Serverless Embeddings with Lambda
Generating embeddings for 500k articles sounds expensive. It is—if you keep a GPU running. It is not—if you use Lambda for batch embedding jobs.
How it works:
- Articles land in Postgres (or S3 as a staging area) with an
embedded_atcolumn set to null. - A scheduled Lambda (or Step Functions workflow) pulls batches of unembedded records.
- Each invocation runs a lightweight embedding model—e.g. via Amazon Bedrock, a small ONNX model in the Lambda layer, or an external API called from Lambda with strict batching.
- Vectors are written back to Postgres;
embedded_atis updated. - Lambda scales to zero when the backlog is cleared.
Cost drivers you control:
- Batch size: Larger batches mean fewer invocations and less cold-start overhead.
- Model choice: Smaller models (384-dim) cost less to run and store; test whether quality is sufficient before jumping to 1536-dim.
- Incremental updates: Only embed new or changed content—never re-embed the full corpus on every deploy.
For the 500k-article deployment, embedding was a one-time batch cost measured in cents, and ongoing re-embeds for new content add pennies per month.
Hybrid Retrieval: Why Vectors Alone Are Not Enough
Pure semantic search misses exact matches—product SKUs, legal citations, error codes, proper nouns. Pure keyword search misses paraphrases and conceptual similarity. Hybrid retrieval combines both and is one of the highest-ROI improvements you can make in a RAG system.
At the center of most high-performing hybrid pipelines is BM25 (Best Matching 25)—a probabilistic ranking function for lexical (keyword) search. BM25 scores documents by term frequency and inverse document frequency, with saturation so that repeating a word 50 times does not dominate the score. It remains a strong baseline decades after it was introduced, and it is often the keyword leg in production RAG systems.
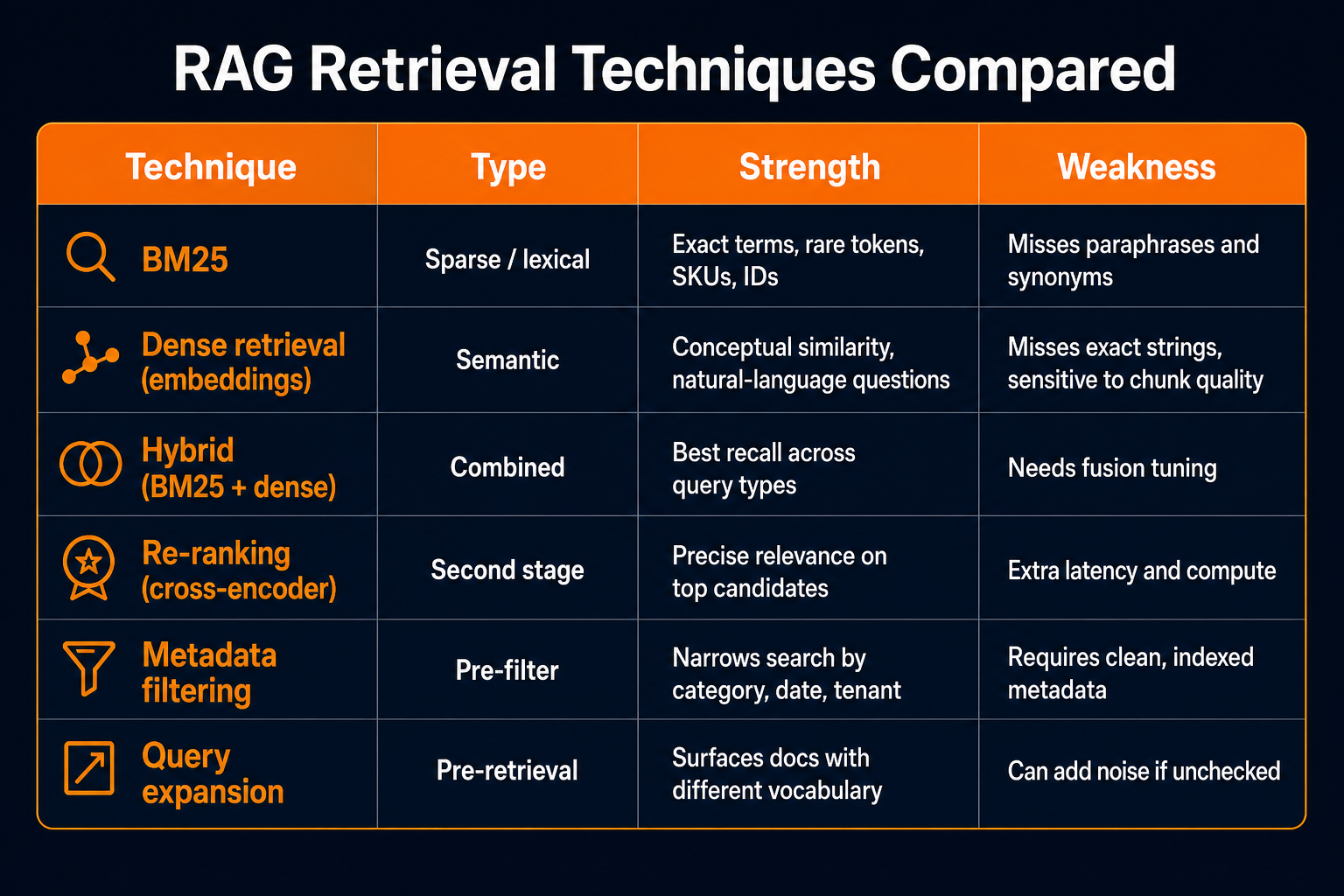
A practical hybrid pattern in Postgres:
- Dense leg: pgvector cosine similarity (or inner product) on chunk embeddings.
- Sparse leg: BM25-style ranking—or PostgreSQL full-text search (
tsvector/tsquery) as a close approximation when you want to stay inside Postgres without OpenSearch. - Fusion: Reciprocal Rank Fusion (RRF) or weighted score combination to merge ranked lists. RRF is robust and does not require normalizing scores across legs.
- Re-ranking (optional): A cross-encoder or LLM re-ranker on the top 20–50 candidates before sending context to the model.
When we need BM25 at scale outside Postgres's built-in FTS, we pair Postgres (source of truth + vectors) with a lightweight search layer—or use extensions like pg_bm25 where available. The principle is the same: two independent retrieval signals, fused before generation.
-- Simplified hybrid query pattern (Postgres FTS as sparse leg)
WITH semantic AS (
SELECT id, title, body,
1 - (embedding <=> query_embedding) AS sem_score
FROM article_chunks
ORDER BY embedding <=> query_embedding
LIMIT 50
),
keyword AS (
SELECT id, title, body,
ts_rank(search_vector, plainto_tsquery('english', :query)) AS kw_score
FROM article_chunks
WHERE search_vector @@ plainto_tsquery('english', :query)
ORDER BY kw_score DESC
LIMIT 50
)
-- Merge with RRF or weighted sum, then return top-k chunks
SELECT * FROM semantic
UNION ALL
SELECT * FROM keyword;
In production we tune the semantic vs keyword weight per content type. News articles skew BM25-heavy; long-form technical docs skew dense-heavy. The same Postgres instance can hold vectors and text indexes—no extra search engine required at moderate scale.
More Techniques That Improve Retrieval
Beyond BM25 + dense hybrid, these patterns consistently improve answer quality without blowing up cost:
Parent-child / contextual chunking — Store small chunks for precise retrieval but attach parent document context (title, section heading, summary) when passing text to the LLM. Fixes the "chunk makes no sense alone" problem.
Hypothetical Document Embeddings (HyDE) — Generate a hypothetical answer to the query, embed that, and search with it. Helps when user questions are short but answers in the corpus are long-form.
Score thresholding — Do not send low-confidence chunks to the LLM. If nothing clears the threshold, say "I don't have enough information" instead of forcing a hallucination.
Deduplication at index time — Near-duplicate articles pollute top-k results. Hash or cluster similar content before embedding.
Eval-driven tuning — Build a set of 50–100 real questions with known correct source documents. For each question, check hit rate@5: did the right chunk show up in the top five results? Track MRR (mean reciprocal rank) to see how high it ranked when it did. Change one variable at a time (chunk size, fusion weight, re-ranker on/off) and compare. This is how you know retrieval improved—not vibes.
For our 500k-article client, hybrid retrieval with tuned fusion mattered more than switching from one embedding model to another. The data was good; the job was surfacing the right piece of it.
Frontend on Vercel (Free Tier)
The user-facing chat or search UI does not need a dedicated backend server. A Next.js app on Vercel's free tier can:
- Serve the search/chat interface
- Call a lightweight API route that queries Postgres (via connection pooling—Neon serverless driver, Supabase, or RDS Proxy)
- Stream LLM responses from Bedrock, OpenAI, or Anthropic
Vercel's free tier covers hobby and moderate internal traffic. For a client-facing product at higher scale, you move to Pro—but the architecture does not change.
Important: Keep embedding and heavy batch work off the Vercel functions. Those belong in Lambda. Vercel handles the thin query + render layer.
What the $3.75/Month Breaks Down To
For the 500k-article client deployment (rounded, actual bill):
- Postgres hosting (~$0–$2): Small managed instance or serverless Postgres within free/low tiers after optimization; storage for vectors is the main variable.
- Lambda executions (~$0.50–$1.50): Batch embedding runs and occasional re-index jobs; well within free tier for steady-state after initial load.
- Embedding API / model inference (~$0.50–$1): One-time bulk embed plus incremental updates; model choice matters more than volume at this scale.
- Vercel ($0): Free tier for the frontend.
- LLM inference at query time: Billed separately per user query—not included in the $3.75 infrastructure number, but controllable with caching and smaller models for retrieval-only flows.
The $3.75/month figure is the infrastructure floor: storage, embeddings pipeline, hosting, and Lambda—not the LLM tokens consumed when users ask questions. That separation is important when pitching RAG to finance: the knowledge base itself can be nearly free to operate.
Architecture Decisions That Saved Money
- Chunk smart, not small: Fewer, larger chunks (512–1024 tokens) mean fewer embeddings to store and query. Over-chunking explodes vector count with little quality gain for many content types.
- Index only what you retrieve: Partial indexes on
embedded_at IS NOT NULL, GIN onsearch_vector, HNSW or IVFFlat on embedding column—tune after you have real query patterns. - Cache frequent queries: Redis or Postgres materialized views for top queries; many internal RAG tools see heavy repeat traffic.
- Defer re-ranking: Start with hybrid retrieval only; add a re-ranker when you have eval data showing you need it.
- Monitor embedding drift: When you change models, plan a migration window—do not run two embedding spaces in parallel indefinitely.
Common Mistakes
- Defaulting to a vector DB because a tutorial said so, before measuring Postgres limits for your scale.
- Embedding on every request instead of pre-computing and storing in Postgres.
- Semantic-only retrieval and wondering why exact-match queries fail.
- Skipping eval and tuning retrieval by gut feel—your retrieval metrics tell the truth.
- Dirty source data and expecting the LLM to fix inconsistent or duplicate articles at query time.
- Running embedding workers 24/7 on EC2 when Lambda batch jobs would cost a fraction.
- Ignoring connection pooling from serverless frontends to Postgres (you will exhaust connections fast).
How to Build It (Step by Step)
- Model your data: articles → chunks → embeddings. Store everything in Postgres with pgvector and
tsvectorcolumns. - Batch-embed with Lambda: Process unembedded rows in batches; track progress in the database.
- Implement hybrid search: semantic + full-text, fused with RRF.
- Deploy frontend on Vercel: API routes query Postgres; stream LLM responses for the generation step.
- Measure and tune: log retrieval hits, run eval sets, adjust chunk size and fusion weights.
At SolarDevs we design and operate this kind of infrastructure for clients who need AI search and RAG without enterprise-scale bills. If you are sitting on a large content corpus and want to know what a deployment like this would cost for your case, schedule a conversation.
Executive Conclusion
A cost-efficient RAG system does not require a dedicated vector database, always-on GPU workers, or expensive managed AI platforms. Postgres + pgvector for storage, BM25 and hybrid retrieval for finding the right context, Lambda for serverless embeddings, and Vercel for the frontend is a proven, production-ready stack. Remember: answers are only as good as the data you retrieve—get retrieval right first. We run this today for a client with 500k+ articles at $3.75/month in infrastructure—and the same patterns scale up cleanly when traffic and query volume grow.
Frequently asked questions
Is pgvector fast enough for 500k vectors?
Yes, with proper indexing (HNSW or IVFFlat) and reasonable top-k limits. At millions of vectors you should benchmark; at hundreds of thousands, Postgres is typically sufficient for interactive RAG.
What embedding model did you use?
Model choice depends on content and language. We prioritize smaller, cost-effective models and validate retrieval quality on a held-out eval set before committing to larger dimensions.
Does $3.75/month include LLM API costs?
No. That figure covers Postgres hosting, Lambda executions, and embedding pipeline infrastructure. LLM inference at query time is billed per token and depends on usage.
Can this work outside AWS?
Yes. The pattern is portable: any serverless functions (Cloud Functions, Workers) for embedding, any managed Postgres with pgvector, any static/edge frontend host.
Need someone to run this?
DevOps retainers with infrastructure monitoring, CI/CD, and clear monthly packages—from $500/mo.
See pricing