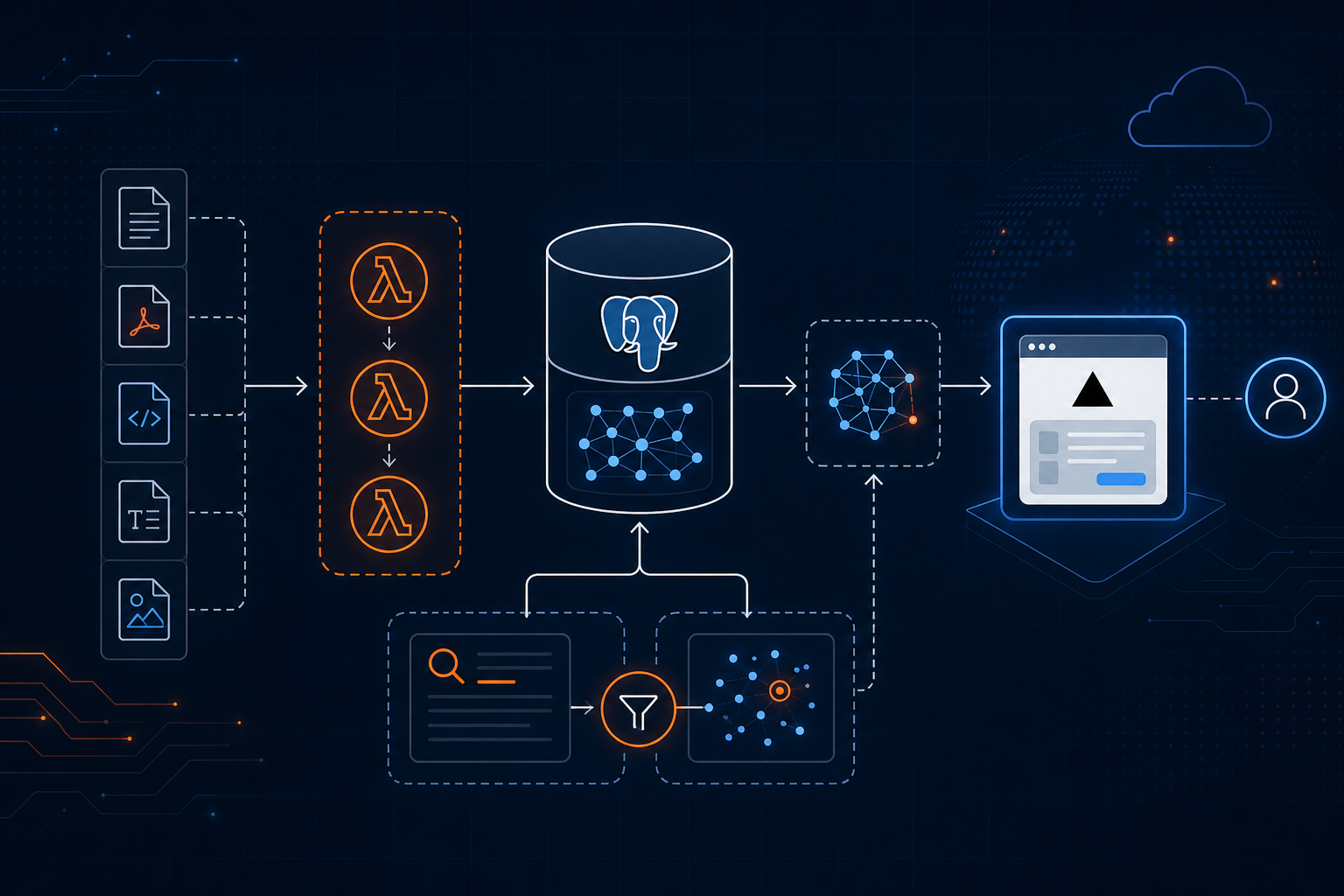
Cómo construir un sistema RAG eficiente en costos con Postgres, Lambda y Vercel

La mayoría de los tutoriales de RAG asumen que vas a levantar una base de datos vectorial, una instancia con GPU y una API de embeddings administrada—y luego te preguntas por qué la factura supera los cientos de dólares antes de llegar a producción. No necesitas ese stack para entregar algo que funcione a escala.
Recientemente construimos un sistema de generación aumentada por recuperación (RAG) para un cliente con más de 500,000 artículos. Toda la plataforma—embeddings, hosting y ejecuciones de Lambda—cuesta $3.75 USD al mes. Este artículo explica la arquitectura y las decisiones que hicieron posible esa cifra.
Tus respuestas solo serán tan buenas como tu recuperación
Los equipos suelen obsesionarse con qué LLM usar—GPT-4, Claude, Llama—y tratar la recuperación como un detalle secundario. Es al revés. La calidad de una respuesta RAG está limitada por la calidad de los chunks que le pasas al modelo. Si la recuperación devuelve contexto irrelevante, desactualizado o incompleto, incluso el mejor LLM alucinará, será vago o evadirá la pregunta. Garbage in, garbage out—pero el "garbage" suele ser un problema de recuperación, no de generación.
En la práctica, la mayoría de demos RAG decepcionantes se remontan a uno de estos puntos:
- Chunks incorrectos recuperados — semánticamente parecidos pero factualmente equivocados para la pregunta
- Chunks faltantes — la respuesta existe en el corpus pero nunca aparece en el top-k
- Datos sucios — duplicados, versiones viejas, formato roto o contenido sin contexto suficiente para entenderse solo
- Sin filtrado por metadatos — se busca en todo el corpus cuando la respuesta vive en una categoría o rango de fechas
La recuperación es el producto. El LLM es la capa de presentación. Invierte tu tiempo de ingeniería en consecuencia: limpia el corpus, chunkea bien y mide si los chunks correctos aparecen en tus primeros resultados antes de cambiar de modelo.
El stack en resumen
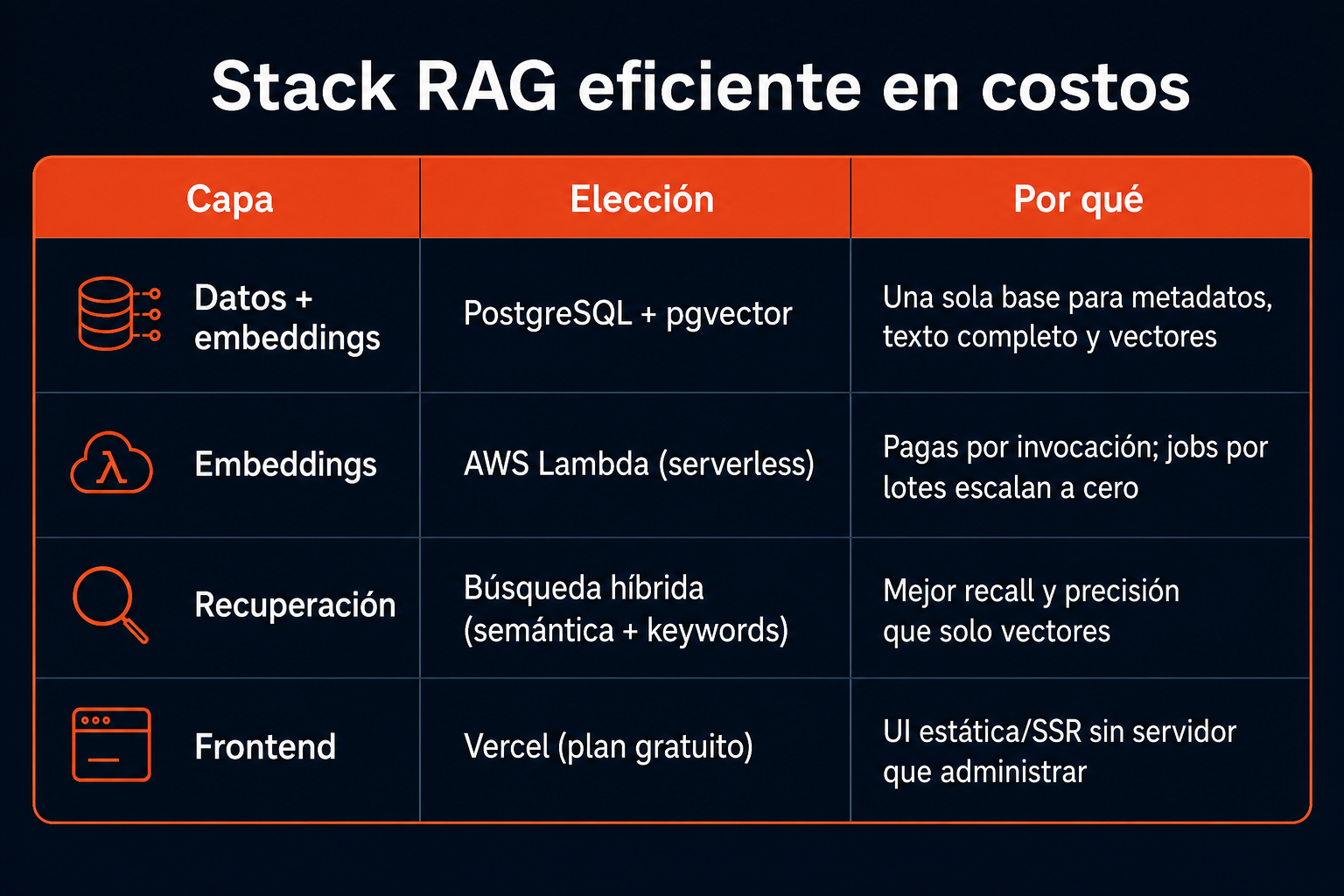
El objetivo no es minimizar costo a costa de calidad. Es evitar pagar infraestructura que no necesitas hasta que realmente la necesites.
Por qué Postgres en lugar de una base vectorial dedicada
Las bases vectoriales dedicadas (Pinecone, Weaviate, Qdrant Cloud, etc.) son excelentes cuando necesitas latencia sub-10ms con miles de millones de vectores y carga concurrente pesada. Para muchas cargas de RAG—herramientas internas, búsqueda de contenido, bases de conocimiento con cientos de miles o pocos millones de documentos—PostgreSQL con pgvector es suficiente y dramáticamente más barato.
Qué almacenas en un solo lugar:
- Metadatos del artículo (título, slug, categoría, fechas)
- Texto completo (para mostrar y búsqueda por keywords)
- Vectores de embedding (típicamente 384–1536 dimensiones según el modelo)
- Opcional: límites de chunks, URLs de origen, flags de control de acceso
Por qué importa para el costo:
- Ya sabes operar Postgres (backups, replicación, monitoreo)
- No hay un segundo sistema que sincronizar, asegurar y pagar
- Postgres administrado en RDS, Neon o Supabase empieza pequeño y escala de forma predecible
- La recuperación híbrida (abajo) es natural:
tsvectorpara keywords convive con columnasvector
Para nuestro cliente, una sola instancia de Postgres almacena los más de 500k registros de artículos, sus chunks y embeddings. Sin duplicar datos entre una vector DB y una base OLTP.
Embeddings serverless con Lambda
Generar embeddings para 500k artículos suena caro. Lo es—si mantienes una GPU encendida. No lo es—si usas Lambda para jobs de embedding por lotes.
Cómo funciona:
- Los artículos llegan a Postgres (o S3 como staging) con una columna
embedded_aten null. - Una Lambda programada (o un flujo de Step Functions) toma lotes de registros sin embedear.
- Cada invocación ejecuta un modelo ligero—por ejemplo vía Amazon Bedrock, un modelo ONNX pequeño en la capa de Lambda, o una API externa llamada desde Lambda con batching estricto.
- Los vectores se escriben de vuelta en Postgres; se actualiza
embedded_at. - Lambda escala a cero cuando se vacía el backlog.
Palancas de costo que controlas:
- Tamaño de lote: Lotes más grandes = menos invocaciones y menos overhead de cold start.
- Elección de modelo: Modelos más pequeños (384-dim) cuestan menos de ejecutar y almacenar; valida si la calidad es suficiente antes de saltar a 1536-dim.
- Actualizaciones incrementales: Solo embebe contenido nuevo o modificado—nunca re-embeber todo el corpus en cada deploy.
En el despliegue de 500k artículos, el embedding inicial fue un costo único medido en centavos, y los re-embeds continuos por contenido nuevo suman centavos al mes.
Recuperación híbrida: por qué los vectores solos no bastan
La búsqueda semántica pura pierde coincidencias exactas—SKUs, citas legales, códigos de error, nombres propios. La búsqueda por keywords pura pierde paráfrasis y similitud conceptual. La recuperación híbrida combina ambas y es una de las mejoras con más ROI en un sistema RAG.
En el centro de la mayoría de pipelines híbridos de alto rendimiento está BM25 (Best Matching 25)—una función de ranking probabilística para búsqueda léxica (por keywords). BM25 puntúa documentos por frecuencia de términos y frecuencia inversa de documento, con saturación para que repetir una palabra 50 veces no domine el score. Sigue siendo un baseline fuerte décadas después de su introducción, y suele ser la pata de keywords en sistemas RAG en producción.
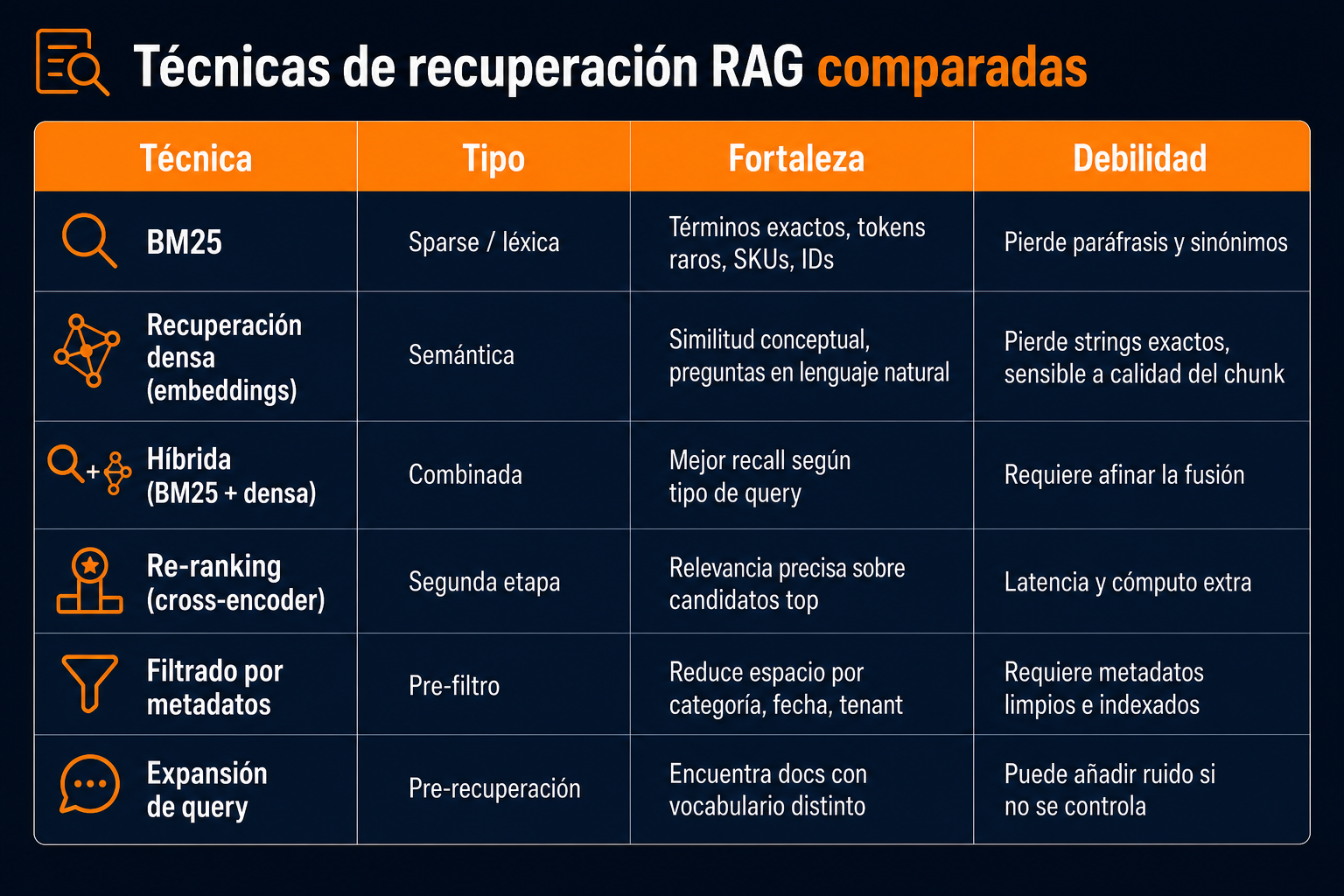
Un patrón híbrido práctico en Postgres:
- Pata densa: similitud coseno (o producto interno) con pgvector sobre embeddings de chunks.
- Pata sparse: ranking estilo BM25—o búsqueda de texto completo de PostgreSQL (
tsvector/tsquery) como aproximación cercana cuando quieres quedarte en Postgres sin OpenSearch. - Fusión: Reciprocal Rank Fusion (RRF) o combinación ponderada de scores para unir listas rankeadas. RRF es robusto y no requiere normalizar scores entre patas.
- Re-ranking (opcional): cross-encoder o re-ranker con LLM sobre los 20–50 candidatos top antes de enviar contexto al modelo.
Cuando necesitamos BM25 a escala fuera del FTS nativo de Postgres, emparejamos Postgres (fuente de verdad + vectores) con una capa de búsqueda ligera—o usamos extensiones como pg_bm25 donde estén disponibles. El principio es el mismo: dos señales de recuperación independientes, fusionadas antes de la generación.
-- Patrón simplificado de consulta híbrida (FTS de Postgres como pata sparse)
WITH semantic AS (
SELECT id, title, body,
1 - (embedding <=> query_embedding) AS sem_score
FROM article_chunks
ORDER BY embedding <=> query_embedding
LIMIT 50
),
keyword AS (
SELECT id, title, body,
ts_rank(search_vector, plainto_tsquery('spanish', :query)) AS kw_score
FROM article_chunks
WHERE search_vector @@ plainto_tsquery('spanish', :query)
ORDER BY kw_score DESC
LIMIT 50
)
-- Fusionar con RRF o suma ponderada, devolver top-k chunks
SELECT * FROM semantic
UNION ALL
SELECT * FROM keyword;
En producción afinamos el peso semántico vs keywords por tipo de contenido. Noticias tienden a BM25; documentación técnica larga tiende a densa. La misma instancia de Postgres puede almacenar vectores e índices de texto—sin motor de búsqueda extra a escala moderada.
Más técnicas que mejoran la recuperación
Más allá de híbrido BM25 + denso, estos patrones mejoran la calidad de respuesta sin disparar el costo:
Chunking padre-hijo / contextual — Almacena chunks pequeños para recuperación precisa pero adjunta contexto del documento padre (título, encabezado de sección, resumen) al pasar texto al LLM. Corrige el problema del "chunk no se entiende solo".
HyDE (Hypothetical Document Embeddings) — Genera una respuesta hipotética a la query, embebe eso y busca con ello. Ayuda cuando las preguntas del usuario son cortas pero las respuestas en el corpus son extensas.
Umbral de score — No envíes chunks de baja confianza al LLM. Si nada supera el umbral, di "no tengo suficiente información" en lugar de forzar una alucinación.
Deduplicación al indexar — Artículos casi duplicados contaminan el top-k. Hashea o agrupa contenido similar antes de embeber.
Afinado basado en evaluación — Construye un set de 50–100 preguntas reales con documentos fuente conocidos. Por cada pregunta, revisa el hit rate@5: ¿apareció el chunk correcto en los cinco primeros resultados? Registra el MRR (mean reciprocal rank) para ver qué tan arriba quedó cuando sí apareció. Cambia una variable a la vez (tamaño de chunk, peso de fusión, re-ranker on/off) y compara. Así sabes que la recuperación mejoró—no por intuición.
Para nuestro cliente con 500k artículos, la recuperación híbrida con fusión afinada importó más que cambiar de un modelo de embedding a otro. Los datos eran buenos; el trabajo era surfacear el fragmento correcto.
Frontend en Vercel (plan gratuito)
La UI de chat o búsqueda no necesita un servidor backend dedicado. Una app Next.js en el plan gratuito de Vercel puede:
- Servir la interfaz de búsqueda/chat
- Llamar una API route ligera que consulta Postgres (vía connection pooling—driver serverless de Neon, Supabase o RDS Proxy)
- Hacer streaming de respuestas del LLM desde Bedrock, OpenAI o Anthropic
El plan gratuito de Vercel cubre tráfico hobby y uso interno moderado. Para un producto cliente a mayor escala, pasas a Pro—pero la arquitectura no cambia.
Importante: Mantén el embedding y el trabajo pesado por lotes fuera de las funciones de Vercel. Eso va en Lambda. Vercel maneja la capa delgada de consulta + render.
Desglose de los $3.75 USD al mes
Para el despliegue del cliente con 500k artículos (redondeado, factura real):
- Hosting Postgres (~$0–$2): Instancia administrada pequeña o Postgres serverless dentro de tiers gratuitos/bajos tras optimización; el almacenamiento de vectores es la variable principal.
- Ejecuciones Lambda (~$0.50–$1.50): Runs de embedding por lotes y jobs ocasionales de re-index; dentro del free tier en estado estable tras la carga inicial.
- API de embeddings / inferencia del modelo (~$0.50–$1): Embed masivo único más actualizaciones incrementales; el modelo importa más que el volumen a esta escala.
- Vercel ($0): Plan gratuito para el frontend.
- Inferencia LLM en tiempo de consulta: Se factura aparte por query de usuario—no incluida en los $3.75 de infraestructura, pero controlable con caché y modelos más pequeños para flujos solo de recuperación.
La cifra de $3.75 USD/mes es el piso de infraestructura: almacenamiento, pipeline de embeddings, hosting y Lambda—no los tokens del LLM cuando los usuarios hacen preguntas. Esa separación es clave al presentar RAG a finanzas: la base de conocimiento en sí puede costar casi nada de operar.
Decisiones de arquitectura que ahorraron dinero
- Chunkear inteligente, no pequeño: Chunks más grandes (512–1024 tokens) = menos embeddings que almacenar y consultar. Sobre-chunkear explota el conteo de vectores con poca ganancia de calidad en muchos tipos de contenido.
- Indexar solo lo que recuperas: Índices parciales en
embedded_at IS NOT NULL, GIN ensearch_vector, HNSW o IVFFlat en la columna de embedding—afina después de tener patrones reales de consulta. - Cachear consultas frecuentes: Redis o vistas materializadas en Postgres para top queries; muchas herramientas RAG internas ven tráfico repetido fuerte.
- Diferir re-ranking: Empieza solo con recuperación híbrida; añade re-ranker cuando tengas datos de evaluación que demuestren que lo necesitas.
- Monitorear drift de embeddings: Al cambiar modelos, planifica una ventana de migración—no corras dos espacios de embedding en paralelo indefinidamente.
Errores comunes
- Elegir una vector DB por defecto porque un tutorial lo dijo, sin medir los límites de Postgres para tu escala.
- Embeber en cada request en lugar de pre-calcular y almacenar en Postgres.
- Recuperación solo semántica y preguntarte por qué fallan las consultas de coincidencia exacta.
- Saltarte la evaluación y afinar recuperación por intuición—tus métricas de recuperación dicen la verdad.
- Datos fuente sucios y esperar que el LLM arregle artículos inconsistentes o duplicados en tiempo de consulta.
- Mantener workers de embedding 24/7 en EC2 cuando jobs por lotes en Lambda costarían una fracción.
- Ignorar connection pooling desde frontends serverless a Postgres (agotarás conexiones rápido).
Cómo construirlo (paso a paso)
- Modela tus datos: artículos → chunks → embeddings. Almacena todo en Postgres con pgvector y columnas
tsvector. - Embebe por lotes con Lambda: Procesa filas sin embedear en batches; rastrea progreso en la base.
- Implementa búsqueda híbrida: semántica + texto completo, fusionada con RRF.
- Despliega frontend en Vercel: API routes consultan Postgres; streaming del LLM para el paso de generación.
- Mide y afina: registra hits de recuperación, corre eval sets, ajusta tamaño de chunk y pesos de fusión.
En SolarDevs diseñamos y operamos este tipo de infraestructura para clientes que necesitan búsqueda con IA y RAG sin facturas de escala enterprise. Si tienes un corpus grande de contenido y quieres saber cuánto costaría un despliegue como este en tu caso, agenda una conversación.
Conclusión ejecutiva
Un sistema RAG eficiente en costos no requiere base vectorial dedicada, workers GPU siempre encendidos ni plataformas de IA administradas caras. Postgres + pgvector para almacenamiento, BM25 y recuperación híbrida para encontrar el contexto correcto, Lambda para embeddings serverless y Vercel para el frontend es un stack probado y listo para producción. Recuerda: las respuestas solo serán tan buenas como los datos que recuperes—acertar en recuperación primero. Lo operamos hoy para un cliente con más de 500k artículos a $3.75 USD/mes en infraestructura—y los mismos patrones escalan limpiamente cuando crecen tráfico y volumen de consultas.
Preguntas frecuentes
¿pgvector es lo suficientemente rápido para 500k vectores?
Sí, con indexación adecuada (HNSW o IVFFlat) y límites razonables de top-k. A millones de vectores conviene hacer benchmark; a cientos de miles, Postgres suele ser suficiente para RAG interactivo.
¿Qué modelo de embedding usaron?
La elección depende del contenido e idioma. Priorizamos modelos pequeños y costo-efectivos y validamos calidad de recuperación en un eval set antes de comprometernos con dimensiones mayores.
¿Los $3.75/mes incluyen costos de API del LLM?
No. Esa cifra cubre hosting Postgres, ejecuciones Lambda e infraestructura del pipeline de embeddings. La inferencia del LLM en tiempo de consulta se factura por token y depende del uso.
¿Funciona fuera de AWS?
Sí. El patrón es portable: cualquier función serverless (Cloud Functions, Workers) para embedding, cualquier Postgres administrado con pgvector, cualquier host de frontend estático/edge.
¿Necesitas a alguien que lo opere?
Retainers de DevOps con monitoreo de infraestructura, CI/CD y paquetes mensuales claros—desde $500/mes.
Ver precios